Atmospheric retrieval with petitRADTRANS¶
This is a tutorial for atmospheric retrievals with petitRADTRANS for which we will use the IRTF spectrum of the L3 type brown dwarf 2MASS J15065441+1321060. The spectrum covers the \(Y\) to \(L\) bands with a resolving power of \(R = 2000\).
Free retrievals are computationally expensive due to the high number of parameter dimensions and the scattering radiative transfer that is important in cloudy atmospheres (see Mollière et al. 2020). Similar to FitModel, the nested sampling supports multiprocessing so it recommended to run the retrievals on a cluster. Before
starting, petitRADTRANS should be installed together with the line and continuum opacities (see installation instructions).
When running a retrieval, it is important to comment out any of the functions that access the Database because writing to the HDF5 file is not possible with multiprocessing. Therefore, the data of the planet or brown dwarf should first be added to the database (e.g. on a local machine), then AtmosphericRetrieval and run_multinest/run_dynesty can be executed (preferably on a cluster), and finally the results can be extracted and plotted while commenting out the retrieval part or using a separate script (e.g. on a local machine).
Getting started¶
We start by adding the library path of MultiNest to the DYLD_LIBRARY_PATH environment (or LD_LIBRARY_PATH on a Linux machine) variable such that PyMultiNest can find the compiled library (see installation instructions).
[1]:
import os
os.environ['DYLD_LIBRARY_PATH'] = '/Users/tomasstolker/applications/MultiNest/lib'
Next, we import the species toolkit and initiate the workflow with an instance of the SpeciesInit class. This will create the HDF5 database and the configuration file in the working folder. If one of these files was already present, then the existing database and/or
configuration will be used.
[2]:
from species import SpeciesInit
from species.data.database import Database
from species.fit.retrieval import AtmosphericRetrieval
from species.plot.plot_mcmc import plot_posterior
from species.plot.plot_retrieval import plot_clouds, plot_opacities, plot_pt_profile
from species.plot.plot_spectrum import plot_spectrum
from species.util.fit_util import get_residuals
[3]:
SpeciesInit()
=======
species
=======
Version: 0.9.1.dev64+g1d42feb.d20250418
Working folder: /Users/tomasstolker/applications/species/docs/tutorials
Creating species_config.ini... [DONE]
Creating species_database.hdf5... [DONE]
Creating data folder... [DONE]
Configuration settings:
- Database: species_database.hdf5
- Data folder: data
- Magnitude of Vega: 0.03
Multiprocessing: mpi4py not installed
[3]:
<species.core.species_init.SpeciesInit at 0x1484c8f80>
Adding data to the database¶
The database is used by species as the central storage for models, data, and results. The data in the HDF5 file is accessed through the Database class. As mentioned already, it is best to add the data beforehand and comment out the database part when executing the retrieval part on a cluster with multi-core processing. To access the HDF5 file, we start by creating an instance of
Database.
[4]:
database = Database()
Next, we will download the IRTF spectrum of 2MASS J15065441+1321060, which is an L3 type field brown dwarf.
[5]:
import urllib.request
urllib.request.urlretrieve('http://irtfweb.ifa.hawaii.edu/~spex/IRTF_Spectral_Library/Data/L3_2MASSJ1506+1321.fits',
'L3_2MASSJ1506+1321.fits')
[5]:
('L3_2MASSJ1506+1321.fits', <http.client.HTTPMessage at 0x1489f9580>)
Now that we have a FITS file with a spectrum, we use the add_object method of Database to add the spectrum and distance of 2MASS J15065441+1321060 to the Database. The distance was calculated from the parallax
of the Gaia Early Data Release 3. We also need to specify the spectral resolution, which is used for smoothing the model spectra to the instrument resolving power. For simplicity, we assume a constant resolving power from \(Y\) to \(L\) band, whereas the actual resolution in the \(L\) band is a bit larger.
[6]:
database.add_object('2MASS J15065441+1321060',
parallax=(85.4250, 0.1902),
app_mag=None,
flux_density=None,
spectrum={'IRTF': ('L3_2MASSJ1506+1321.fits', None, 2000.)},
deredden=None)
----------
Add object
----------
Object name: 2MASS J15065441+1321060
Units: None
Deredden: None
Parallax (mas) = 85.42 +/- 0.19
Spectra:
- Spectrum:
- Database tag: IRTF
- Filename: L3_2MASSJ1506+1321.fits
- Data shape: (5399, 3)
- Wavelength range (um): 0.93 - 4.10
- Mean flux (W m-2 um-1): 7.79e-15
- Mean error (W m-2 um-1): 1.84e-16
- Instrument resolution:
- IRTF: 2000.0
/Users/tomasstolker/applications/species/species/data/database.py:1470: UserWarning: Transposing the data of IRTF because the first instead of the second axis has a length of 3.
warnings.warn(
/Users/tomasstolker/applications/species/species/data/database.py:1491: UserWarning: Found 804 fluxes with NaN in the data of IRTF. Removing the spectral fluxes that contain a NaN.
warnings.warn(
Now that the data is present in the database, we can run the retrieval! Since running the actual retrieval takes quite some time, we will simply download the results (408 MB) that were stored in the output_folder (see below) after running the retrieval on a cluster.
[7]:
import urllib.request
urllib.request.urlretrieve('https://home.strw.leidenuniv.nl/~stolker/species/retrieval.tgz',
'retrieval.tgz')
[7]:
('retrieval.tgz', <http.client.HTTPMessage at 0x1489f9220>)
Let’s unpack this compressed TAR archive.
[8]:
import tarfile
with tarfile.open('retrieval.tgz') as tar:
tar.extractall('./', filter='data')
Atmospheric retrieval of abundances, clouds, and P-T structure¶
A retrieval is started by first creating an instance of AtmosphericRetrieval. Several parameters need to be provided, including the database tag to the data (i.e. object_name), the line and cloud species that should be included in the forward model (i.e. line_species and cloud_species), and if scattering should be turned on with the radiative transfer (i.e scattering).
Scattering will make the calculation of the forward model much slower but is important for cloudy atmospheres. In this example, we use the low-resolution mode of petitRADTRANS (i.e. res_mode='c-k') because it runs fastest, even though the data warrants the use of the high-resolution mode (i.e. res_mode='c-k' in combination with lbl_opacity_sampling), which would give a more accurate result.
[9]:
retrieve = AtmosphericRetrieval(object_name='2MASS J15065441+1321060',
line_species=['12C-16O__HITEMP', '1H2-16O__HITRAN', '12C-1H4__Hargreaves',
'14N-1H3__HITRAN', '12C-16O2__HITEMP', '23Na__NewAllard',
'39K__Allard', '48Ti-16O__Plez', '51V-16O__Plez',
'56Fe-1H__MoLLIST', '1H2-32S__HITRAN'],
cloud_species=['MgSiO3(s)_crystalline__DHS', 'Fe(s)_crystalline__DHS'],
res_mode='lbl',
output_folder='multinest',
wavel_range=(0.9, 4.2),
scattering=True,
inc_spec=True,
inc_phot=False,
pressure_grid='smaller',
weights=None,
ccf_species=None,
max_pressure=1e3,
lbl_opacity_sampling=10)
---------------------
Atmospheric retrieval
---------------------
Object: 2MASS J15065441+1321060
Parallax (mas): 85.4250 +/- 0.1902
Line species:
- 12C-16O__HITEMP
- 1H2-16O__HITRAN
- 12C-1H4__Hargreaves
- 14N-1H3__HITRAN
- 12C-16O2__HITEMP
- 23Na__NewAllard
- 39K__Allard
- 48Ti-16O__Plez
- 51V-16O__Plez
- 56Fe-1H__MoLLIST
- 1H2-32S__HITRAN
Cloud species:
- MgSiO3(s)_crystalline__DHS
- Fe(s)_crystalline__DHS
Cross-correlation species: None
Scattering: True
Opacity mode: line-by-line (lambda/Dlambda = 1,000,000)
Spectra:
- IRTF
Wavelength range (um) = 0.93 - 4.10
Spectral resolution = 2000.00
Initiating 180 pressure levels (bar): 1.00e-06 - 1.00e+03
Weights for the log-likelihood function:
- IRTF = 1.00e+00
Next, we setup the parameters for the forward model by using the setup_retrieval method, such as specifying the type of chemistry with chemistry and the P-T parametrization with pt_profile.
The dictionary of bounds includes the uniform and log-uniform distruted priors for the model parameters. The latter is for parameters typically starting with log_. The setup_retrieval method has an additional parameter called prior, which can be used for normal distributed priors (including the planet mass).
Not all the parameters that are included in bounds are mandatory so some will only be used in the forward model if the parameters are included in the dictionary. Furthermore, there are various parametrizations for the clouds available. The model that is used is partially determined by the parameters that are included. In fact, in the example below, only the surface gravity (logg) and radius (radius) are mandatory parameters.
In this case, the C/O ratio and metallicity are free parameter because we are using a chemical equilibrium model. We also retrieve the cloud mass fractions relative to the equilibrium abundances (mgsio3_fraction and fe_fraction), the sedimentation parameter (fsed; determines the vertical extent of the clouds), the eddy diffusion coefficient (log_kzz; determines the particles sizes of the clouds), and the width of the log-normal size distribution (sigma_lnorm) for the cloud
particles.
[10]:
retrieve.setup_retrieval(bounds={'logg': (2.5, 6.0),
'c_o_ratio': (0.1, 1.5),
'metallicity': (-3., 3.),
'radius': (0.5, 2.),
'MgSiO3(s)_crystalline__DHS_fraction': (-2., 1.),
'Fe(s)_crystalline__DHS_fraction': (-2., 1.),
'fsed': (0., 10.),
'log_kzz': (2., 15.),
'sigma_lnorm': (1.2, 5.),
'pt_smooth': (0., 2.),
'vsini': (0., 100.),
'rad_vel': (-30., 30.)},
chemistry='equilibrium',
quenching='pressure',
pt_profile='monotonic',
fit_corr=None,
cross_corr=None,
check_isothermal=False,
pt_smooth=None,
abund_smooth=None,
check_flux=None,
temp_nodes=15,
abund_nodes=None,
prior=None,
check_phot_press=None,
apply_rad_vel=['IRTF'],
apply_vsini=['IRTF'],
global_fsed=True)
---------------
Retrieval setup
---------------
P-T profile: monotonic
Chemistry: equilibrium
Quenching: pressure
Fit covariances: None
Fit RV: ['IRTF']
Fit vsin(i): ['IRTF']
Uniform priors (min, max):
- logg = (2.5, 6.0)
- c_o_ratio = (0.1, 1.5)
- metallicity = (-3.0, 3.0)
- radius = (0.5, 2.0)
- MgSiO3(s)_crystalline__DHS_fraction = (-2.0, 1.0)
- Fe(s)_crystalline__DHS_fraction = (-2.0, 1.0)
- fsed = (0.0, 10.0)
- log_kzz = (2.0, 15.0)
- sigma_lnorm = (1.2, 5.0)
- pt_smooth = (0.0, 2.0)
- vsini = (0.0, 100.0)
- rad_vel = (-30.0, 30.0)
Importing petitRADTRANS... [DONE]
Number of pressure levels used with the radiative transfer: 60
Loading Radtrans opacities...
Loading line opacities of species '12C-16O__HITEMP' from file '/Users/tomasstolker/.petitradtrans/input_data/opacities/lines/line_by_line/CO/12C-16O/12C-16O__HITEMP.R1e6_0.3-28mu.xsec.petitRADTRANS.h5'... Done.
Loading line opacities of species '1H2-16O__HITRAN' from file '/Users/tomasstolker/.petitradtrans/input_data/opacities/lines/line_by_line/H2O/1H2-16O/1H2-16O__HITRAN.R1e6_0.3-28mu.xsec.petitRADTRANS.h5'... Done.
Loading line opacities of species '12C-1H4__Hargreaves' from file '/Users/tomasstolker/.petitradtrans/input_data/opacities/lines/line_by_line/CH4/12C-1H4/12C-1H4__Hargreaves.R1e6_0.3-28mu.xsec.petitRADTRANS.h5'... Done.
Loading line opacities of species '14N-1H3__HITRAN' from file '/Users/tomasstolker/.petitradtrans/input_data/opacities/lines/line_by_line/NH3/14N-1H3/14N-1H3__HITRAN.R1e6_0.3-28mu.xsec.petitRADTRANS.h5'... Done.
Loading line opacities of species '12C-16O2__HITEMP' from file '/Users/tomasstolker/.petitradtrans/input_data/opacities/lines/line_by_line/CO2/12C-16O2/12C-16O2__HITEMP.R1e6_0.3-28mu.xsec.petitRADTRANS.h5'... Done.
Loading line opacities of species '23Na__NewAllard' from file '/Users/tomasstolker/.petitradtrans/input_data/opacities/lines/line_by_line/Na/23Na/23Na__NewAllard.R1e6_0.3-28mu.xsec.petitRADTRANS.h5'... Done.
Loading line opacities of species '39K__Allard' from file '/Users/tomasstolker/.petitradtrans/input_data/opacities/lines/line_by_line/K/39K/39K__Allard.R1e6_0.3-28mu.xsec.petitRADTRANS.h5'... Done.
Loading line opacities of species '48Ti-16O__Plez' from file '/Users/tomasstolker/.petitradtrans/input_data/opacities/lines/line_by_line/TiO/48Ti-16O/48Ti-16O__Plez.R1e6_0.3-28mu.xsec.petitRADTRANS.h5'... Done.
Loading line opacities of species '51V-16O__Plez' from file '/Users/tomasstolker/.petitradtrans/input_data/opacities/lines/line_by_line/VO/51V-16O/51V-16O__Plez.R1e6_0.3-28mu.xsec.petitRADTRANS.h5'... Done.
Loading line opacities of species '56Fe-1H__MoLLIST' from file '/Users/tomasstolker/.petitradtrans/input_data/opacities/lines/line_by_line/FeH/56Fe-1H/56Fe-1H__MoLLIST.R1e6_0.3-28mu.xsec.petitRADTRANS.h5'... Done.
Loading line opacities of species '1H2-32S__HITRAN' from file '/Users/tomasstolker/.petitradtrans/input_data/opacities/lines/line_by_line/H2S/1H2-32S/1H2-32S__HITRAN.R1e6_0.3-28mu.xsec.petitRADTRANS.h5'... Done.
Successfully loaded all line opacities
Loading CIA opacities for H2-H2 from file '/Users/tomasstolker/.petitradtrans/input_data/opacities/continuum/collision_induced_absorptions/H2--H2/H2--H2-NatAbund/H2--H2-NatAbund__BoRi.R831_0.6-250mu.ciatable.petitRADTRANS.h5'... Done.
Loading CIA opacities for H2-He from file '/Users/tomasstolker/.petitradtrans/input_data/opacities/continuum/collision_induced_absorptions/H2--He/H2--He-NatAbund/H2--He-NatAbund__BoRi.DeltaWavenumber2_0.5-500mu.ciatable.petitRADTRANS.h5'... Done.
Successfully loaded all CIA opacities
Loading opacities of cloud species 'MgSiO3(s)_crystalline__DHS' from file '/Users/tomasstolker/.petitradtrans/input_data/opacities/continuum/clouds/MgSiO3(s)_crystalline_000/Mg-Si-O3-NatAbund(s)_crystalline_000/Mg-Si-O3-NatAbund(s)_crystalline_000__DHS.R39_0.1-250mu.cotable.petitRADTRANS.h5' (crystalline_000, using DHS scattering)... Done.
Loading opacities of cloud species 'Fe(s)_crystalline__DHS' from file '/Users/tomasstolker/.petitradtrans/input_data/opacities/continuum/clouds/Fe(s)_crystalline_000/Fe-NatAbund(s)_crystalline_000/Fe-NatAbund(s)_crystalline_000__DHS.R39_0.1-250mu.cotable.petitRADTRANS.h5' (crystalline_000, using DHS scattering)... Done.
Successfully loaded all clouds opacities
Successfully loaded all opacities
Fitting 29 parameters:
- logg
- radius
- parallax
- t0
- t1
- t2
- t3
- t4
- t5
- t6
- t7
- t8
- t9
- t10
- t11
- t12
- t13
- t14
- metallicity
- c_o_ratio
- log_p_quench
- fsed
- log_kzz
- sigma_lnorm
- MgSiO3(s)_crystalline__DHS_fraction
- Fe(s)_crystalline__DHS_fraction
- pt_smooth
- rad_vel
- vsini
Storing the model parameters: multinest/params.json
Storing the Radtrans arguments: multinest/radtrans.json
Loading chemical equilibrium chemistry table from file '/Users/tomasstolker/.petitradtrans/input_data/pre_calculated_chemistry/equilibrium_chemistry/equilibrium_chemistry.chemtable.petitRADTRANS.h5'... Done.
Now we can run the actual retrieval with run_multinest or run_dynesty. The nested sampling algorithm supports multiprocessing so make sure to use MPI when running on a cluster. For testing purpose this is not required though since the retrieval also runs without MPI.
With plotting=True, each model iteration would save several plots, which can be inspected for testing purpose. It is best set the argument to False when running the full retrieval. There is also the possibility to continue a retrieval that was interrupted by setting resume=True (as long as the input parameters have not changed) because MultiNest and Dynesty continuously update the data in the output_folder.
Since we have downloaded the completed retrieval results, we will set resume=True. In this case, the retrieval will finish directly because the posterior distribution was already fully sampled at the requested accuracy, so in principle the run_multinest could also be skipped.
[11]:
retrieve.run_multinest(n_live_points=500,
resume=True,
const_efficiency_mode=True,
sampling_efficiency=0.05,
evidence_tolerance=0.5,
out_basename=None,
plotting=False)
------------------------------
Nested sampling with MultiNest
------------------------------
*****************************************************
MultiNest v3.10
Copyright Farhan Feroz & Mike Hobson
Release Jul 2015
no. of live points = 500
dimensionality = 29
running in constant efficiency mode
resuming from previous job
*****************************************************
Starting MultiNest
Acceptance Rate: 0.090876
Replacements: 97576
Total Samples: 1073724
Nested Sampling ln(Z): 132921.598815
Importance Nested Sampling ln(Z): 132924.656645 +/- 0.023289
ln(ev)= 132921.68838718894 +/- 0.61099839359619657
Total Likelihood Evaluations: 1073724
Sampling finished. Exiting MultiNest
As expected, the retrieval finishes directly after starting because it read the completed results from the output_folder.
Nested sampling output folder¶
The output data from the nested sampling with MultiNest is stored in the output_folder. After running the retrieval, we can use the add_retrieval method of Database to store the posterior samples from the output_folder, together with the relevant attributes, in the HDF5 database.
The argument of tag is used as name tag in the database and will be used later on for processing the results. It is also possible to calculate \(T_\mathrm{eff}\) for each sample but this takes a long time because each spectrum needs to be calculated over a broad wavelength range.
[12]:
database.add_retrieval(tag='2mj1506',
output_folder='multinest',
inc_teff=False)
Storing samples in the database... [DONE]
Loading chemical equilibrium chemistry table from file '/Users/tomasstolker/.petitradtrans/input_data/pre_calculated_chemistry/equilibrium_chemistry/equilibrium_chemistry.chemtable.petitRADTRANS.h5'... Done.
Instead of using the inc_teff parameter of add_retrieval, we use the get_retrieval_teff method to estimate \(T_\mathrm{eff}\) from a small number of samples (30 in the example below). The value is stored in the database as attribute of the group that is specified with the argument of tag.
[13]:
_, _ = database.get_retrieval_teff(tag='2mj1506',
wavel_range=(0.5, 27.),
random=100)
Calculating Teff from 100 posterior samples...
Importing petitRADTRANS... [DONE]
Loading Radtrans opacities...
Loading line opacities of species '12C-16O__HITEMP' from file '/Users/tomasstolker/.petitradtrans/input_data/opacities/lines/line_by_line/CO/12C-16O/12C-16O__HITEMP.R1e6_0.3-28mu.xsec.petitRADTRANS.h5'... Done.
Loading line opacities of species '1H2-16O__HITRAN' from file '/Users/tomasstolker/.petitradtrans/input_data/opacities/lines/line_by_line/H2O/1H2-16O/1H2-16O__HITRAN.R1e6_0.3-28mu.xsec.petitRADTRANS.h5'... Done.
Loading line opacities of species '12C-1H4__Hargreaves' from file '/Users/tomasstolker/.petitradtrans/input_data/opacities/lines/line_by_line/CH4/12C-1H4/12C-1H4__Hargreaves.R1e6_0.3-28mu.xsec.petitRADTRANS.h5'... Done.
Loading line opacities of species '14N-1H3__HITRAN' from file '/Users/tomasstolker/.petitradtrans/input_data/opacities/lines/line_by_line/NH3/14N-1H3/14N-1H3__HITRAN.R1e6_0.3-28mu.xsec.petitRADTRANS.h5'... Done.
Loading line opacities of species '12C-16O2__HITEMP' from file '/Users/tomasstolker/.petitradtrans/input_data/opacities/lines/line_by_line/CO2/12C-16O2/12C-16O2__HITEMP.R1e6_0.3-28mu.xsec.petitRADTRANS.h5'... Done.
Loading line opacities of species '23Na__NewAllard' from file '/Users/tomasstolker/.petitradtrans/input_data/opacities/lines/line_by_line/Na/23Na/23Na__NewAllard.R1e6_0.3-28mu.xsec.petitRADTRANS.h5'... Done.
Loading line opacities of species '39K__Allard' from file '/Users/tomasstolker/.petitradtrans/input_data/opacities/lines/line_by_line/K/39K/39K__Allard.R1e6_0.3-28mu.xsec.petitRADTRANS.h5'... Done.
Loading line opacities of species '48Ti-16O__Plez' from file '/Users/tomasstolker/.petitradtrans/input_data/opacities/lines/line_by_line/TiO/48Ti-16O/48Ti-16O__Plez.R1e6_0.3-28mu.xsec.petitRADTRANS.h5'... Done.
Loading line opacities of species '51V-16O__Plez' from file '/Users/tomasstolker/.petitradtrans/input_data/opacities/lines/line_by_line/VO/51V-16O/51V-16O__Plez.R1e6_0.3-28mu.xsec.petitRADTRANS.h5'... Done.
Loading line opacities of species '56Fe-1H__MoLLIST' from file '/Users/tomasstolker/.petitradtrans/input_data/opacities/lines/line_by_line/FeH/56Fe-1H/56Fe-1H__MoLLIST.R1e6_0.3-28mu.xsec.petitRADTRANS.h5'... Done.
Loading line opacities of species '1H2-32S__HITRAN' from file '/Users/tomasstolker/.petitradtrans/input_data/opacities/lines/line_by_line/H2S/1H2-32S/1H2-32S__HITRAN.R1e6_0.3-28mu.xsec.petitRADTRANS.h5'... Done.
Successfully loaded all line opacities
Loading CIA opacities for H2-H2 from file '/Users/tomasstolker/.petitradtrans/input_data/opacities/continuum/collision_induced_absorptions/H2--H2/H2--H2-NatAbund/H2--H2-NatAbund__BoRi.R831_0.6-250mu.ciatable.petitRADTRANS.h5'... Done.
Loading CIA opacities for H2-He from file '/Users/tomasstolker/.petitradtrans/input_data/opacities/continuum/collision_induced_absorptions/H2--He/H2--He-NatAbund/H2--He-NatAbund__BoRi.DeltaWavenumber2_0.5-500mu.ciatable.petitRADTRANS.h5'... Done.
Successfully loaded all CIA opacities
Loading opacities of cloud species 'MgSiO3(s)_crystalline__DHS' from file '/Users/tomasstolker/.petitradtrans/input_data/opacities/continuum/clouds/MgSiO3(s)_crystalline_000/Mg-Si-O3-NatAbund(s)_crystalline_000/Mg-Si-O3-NatAbund(s)_crystalline_000__DHS.R39_0.1-250mu.cotable.petitRADTRANS.h5' (crystalline_000, using DHS scattering)... Done.
Loading opacities of cloud species 'Fe(s)_crystalline__DHS' from file '/Users/tomasstolker/.petitradtrans/input_data/opacities/continuum/clouds/Fe(s)_crystalline_000/Fe-NatAbund(s)_crystalline_000/Fe-NatAbund(s)_crystalline_000__DHS.R39_0.1-250mu.cotable.petitRADTRANS.h5' (crystalline_000, using DHS scattering)... Done.
Successfully loaded all clouds opacities
Successfully loaded all opacities
Loading chemical equilibrium chemistry table from file '/Users/tomasstolker/.petitradtrans/input_data/pre_calculated_chemistry/equilibrium_chemistry/equilibrium_chemistry.chemtable.petitRADTRANS.h5'... Done.
Getting posterior spectra 100/100... [DONE]
Teff (K) = 1870.87 (-0.30 +0.28)
log(L/Lsun) = -4.00 (-0.00 +0.00)
Storing Teff (K) as attribute of results/fit/2mj1506/samples... [DONE]
Storing log(L/Lsun) as attribute of results/fit/2mj1506/samples... [DONE]
Plotting the posterior distributions¶
We can now read the posterior samples from the database and use the plot functionalities to visualize the results. Let’s first plot the marginalized posterior distributions with the plot_posterior function. This function makes use of the corner.py package. Since there are many free parameters, we will exclude the parameters for P-T profile by setting
inc_pt_param=False. By setting output=None, the plot is shown instead of written to a file.
[14]:
fig = plot_posterior(tag='2mj1506',
offset=(-0.3, -0.35),
vmr=False,
inc_luminosity=False,
inc_mass=False,
inc_pt_param=False,
inc_loglike=False,
output=None)
---------------------
Get posterior samples
---------------------
Database tag: 2mj1506
Random samples: None
Samples shape: (6301, 29)
Parameters:
- logg
- radius
- parallax
- t0
- t1
- t2
- t3
- t4
- t5
- t6
- t7
- t8
- t9
- t10
- t11
- t12
- t13
- t14
- metallicity
- c_o_ratio
- log_p_quench
- fsed
- log_kzz
- sigma_lnorm
- MgSiO3(s)_crystalline__DHS_fraction
- Fe(s)_crystalline__DHS_fraction
- pt_smooth
- rad_vel
- vsini
----------------------------
Plot posterior distributions
----------------------------
Database tag: 2mj1506
Object type: planet
Manual parameters: None
Model type: retrieval
Model name: petitradtrans
Median parameters:
- logg = 5.75
- radius = 0.92
- parallax = 85.45
- t0 = 38.41
- t1 = 152.49
- t2 = 239.38
- t3 = 400.39
- t4 = 449.54
- t5 = 874.41
- t6 = 1198.74
- t7 = 1221.60
- t8 = 1338.60
- t9 = 1820.52
- t10 = 1833.47
- t11 = 2331.00
- t12 = 3675.19
- t13 = 4880.06
- t14 = 6687.26
- metallicity = 1.03
- c_o_ratio = 0.60
- log_p_quench = -0.20
- fsed = 9.28
- log_kzz = 5.55
- sigma_lnorm = 1.20
- MgSiO3(s)_crystalline__DHS_fraction = -0.47
- Fe(s)_crystalline__DHS_fraction = 0.99
- pt_smooth = 0.51
- rad_vel = -9.05
- vsini = 81.01
Sample with the maximum likelihood:
- logg = 5.75
- radius = 0.92
- parallax = 85.46
- t0 = 2.64
- t1 = 183.40
- t2 = 256.97
- t3 = 380.15
- t4 = 476.10
- t5 = 846.87
- t6 = 1203.73
- t7 = 1215.16
- t8 = 1337.61
- t9 = 1822.37
- t10 = 1834.86
- t11 = 2325.28
- t12 = 3683.37
- t13 = 4890.07
- t14 = 6739.59
- metallicity = 1.03
- c_o_ratio = 0.60
- log_p_quench = -0.21
- fsed = 9.31
- log_kzz = 5.55
- sigma_lnorm = 1.20
- MgSiO3(s)_crystalline__DHS_fraction = -0.46
- Fe(s)_crystalline__DHS_fraction = 0.99
- pt_smooth = 0.51
- rad_vel = -9.20
- vsini = 81.63
Parameters included in corner plot:
- logg
- radius
- parallax
- metallicity
- c_o_ratio
- log_p_quench
- fsed
- log_kzz
- sigma_lnorm
- MgSiO3(s)_crystalline__DHS_fraction
- Fe(s)_crystalline__DHS_fraction
- pt_smooth
- rad_vel
- vsini

The plot_posterior function returned the Figure object of the plot. The functionalities of Matplotlib can be used for further customization of the plot.
ReadRadtrans and random spectra¶
In order to post-process the posterior samples, we need to recreate the Radtrans object of petitRADTRANS. Todo so, we use the get_retrieval_spectra method of Database to create an instance of
ReadRadtrans with the adopted parameters that were set with the retrieval. The Radtrans object is stored as an attribute of the ReadRadtrans object. The ReadRadtrans object can simply be passed to some of the species functions later on and can typically be ignored by the user. The method also returns a list of random spectra (30 in the example below) that have been
recalculated at a resolving power of \(R = 2000\). Each spectrum is stored in a ModelBox together with the atmospheric parameters.
[15]:
samples, radtrans = database.get_retrieval_spectra(tag='2mj1506',
random=30,
wavel_range=(0.9, 4.0),
spec_res=2000.)
Importing petitRADTRANS... [DONE]
Loading Radtrans opacities...
Loading line opacities of species '12C-16O__HITEMP' from file '/Users/tomasstolker/.petitradtrans/input_data/opacities/lines/line_by_line/CO/12C-16O/12C-16O__HITEMP.R1e6_0.3-28mu.xsec.petitRADTRANS.h5'... Done.
Loading line opacities of species '1H2-16O__HITRAN' from file '/Users/tomasstolker/.petitradtrans/input_data/opacities/lines/line_by_line/H2O/1H2-16O/1H2-16O__HITRAN.R1e6_0.3-28mu.xsec.petitRADTRANS.h5'... Done.
Loading line opacities of species '12C-1H4__Hargreaves' from file '/Users/tomasstolker/.petitradtrans/input_data/opacities/lines/line_by_line/CH4/12C-1H4/12C-1H4__Hargreaves.R1e6_0.3-28mu.xsec.petitRADTRANS.h5'... Done.
Loading line opacities of species '14N-1H3__HITRAN' from file '/Users/tomasstolker/.petitradtrans/input_data/opacities/lines/line_by_line/NH3/14N-1H3/14N-1H3__HITRAN.R1e6_0.3-28mu.xsec.petitRADTRANS.h5'... Done.
Loading line opacities of species '12C-16O2__HITEMP' from file '/Users/tomasstolker/.petitradtrans/input_data/opacities/lines/line_by_line/CO2/12C-16O2/12C-16O2__HITEMP.R1e6_0.3-28mu.xsec.petitRADTRANS.h5'... Done.
Loading line opacities of species '23Na__NewAllard' from file '/Users/tomasstolker/.petitradtrans/input_data/opacities/lines/line_by_line/Na/23Na/23Na__NewAllard.R1e6_0.3-28mu.xsec.petitRADTRANS.h5'... Done.
Loading line opacities of species '39K__Allard' from file '/Users/tomasstolker/.petitradtrans/input_data/opacities/lines/line_by_line/K/39K/39K__Allard.R1e6_0.3-28mu.xsec.petitRADTRANS.h5'... Done.
Loading line opacities of species '48Ti-16O__Plez' from file '/Users/tomasstolker/.petitradtrans/input_data/opacities/lines/line_by_line/TiO/48Ti-16O/48Ti-16O__Plez.R1e6_0.3-28mu.xsec.petitRADTRANS.h5'... Done.
Loading line opacities of species '51V-16O__Plez' from file '/Users/tomasstolker/.petitradtrans/input_data/opacities/lines/line_by_line/VO/51V-16O/51V-16O__Plez.R1e6_0.3-28mu.xsec.petitRADTRANS.h5'... Done.
Loading line opacities of species '56Fe-1H__MoLLIST' from file '/Users/tomasstolker/.petitradtrans/input_data/opacities/lines/line_by_line/FeH/56Fe-1H/56Fe-1H__MoLLIST.R1e6_0.3-28mu.xsec.petitRADTRANS.h5'... Done.
Loading line opacities of species '1H2-32S__HITRAN' from file '/Users/tomasstolker/.petitradtrans/input_data/opacities/lines/line_by_line/H2S/1H2-32S/1H2-32S__HITRAN.R1e6_0.3-28mu.xsec.petitRADTRANS.h5'... Done.
Successfully loaded all line opacities
Loading CIA opacities for H2-H2 from file '/Users/tomasstolker/.petitradtrans/input_data/opacities/continuum/collision_induced_absorptions/H2--H2/H2--H2-NatAbund/H2--H2-NatAbund__BoRi.R831_0.6-250mu.ciatable.petitRADTRANS.h5'... Done.
Loading CIA opacities for H2-He from file '/Users/tomasstolker/.petitradtrans/input_data/opacities/continuum/collision_induced_absorptions/H2--He/H2--He-NatAbund/H2--He-NatAbund__BoRi.DeltaWavenumber2_0.5-500mu.ciatable.petitRADTRANS.h5'... Done.
Successfully loaded all CIA opacities
Loading opacities of cloud species 'MgSiO3(s)_crystalline__DHS' from file '/Users/tomasstolker/.petitradtrans/input_data/opacities/continuum/clouds/MgSiO3(s)_crystalline_000/Mg-Si-O3-NatAbund(s)_crystalline_000/Mg-Si-O3-NatAbund(s)_crystalline_000__DHS.R39_0.1-250mu.cotable.petitRADTRANS.h5' (crystalline_000, using DHS scattering)... Done.
Loading opacities of cloud species 'Fe(s)_crystalline__DHS' from file '/Users/tomasstolker/.petitradtrans/input_data/opacities/continuum/clouds/Fe(s)_crystalline_000/Fe-NatAbund(s)_crystalline_000/Fe-NatAbund(s)_crystalline_000__DHS.R39_0.1-250mu.cotable.petitRADTRANS.h5' (crystalline_000, using DHS scattering)... Done.
Successfully loaded all clouds opacities
Successfully loaded all opacities
Loading chemical equilibrium chemistry table from file '/Users/tomasstolker/.petitradtrans/input_data/pre_calculated_chemistry/equilibrium_chemistry/equilibrium_chemistry.chemtable.petitRADTRANS.h5'... Done.
Getting posterior spectra 30/30... [DONE]
Plotting the P-T profiles, opacities, and clouds¶
We will now create some additional plots for analyzing the retrieved atmospheric structure. First, we will use the plot_pt_profile function for selecting random samples (100 in the example below) from the posterior distribution and recalculating the P-T profiles. We set the database tag were the posterior samples and attributes are stored and additionally the extra_axis (i.e. the
top \(x\) axis) that we want to use for showing the average particle radius of the MgSiO\(_3\) and Fe clouds as function of pressure. These are average particle sizes but particle smaller than 1 nm are excluded from the actual size distribution. The condensation profiles of these cloud species are also shown with colored dashed lines.
The parametrization of the P-T profiles used 15 free nodes that are monotonically increasing with pressure and shown for the median parameters. The free nodes are interpolated and smoothed with a Gaussian kernel of \(\sigma = 0.3\) dex in pressure, hence there is a slight difference between the sampled temperature nodes and the actual P-T profiles.
The P-T profile from the median sample is shown with a black solid line while the 100 random samples are shown with thin gray lines. Given the large number of spectral data points, we get a very good constraints on all retrieved parameters, so it would probably warrant the inclusion of additional parameters to give the model more freedom.
[16]:
fig = plot_pt_profile(tag='2mj1506',
random=100,
xlim=(0., 10000.),
offset=(-0.07, -0.14),
output=None,
radtrans=radtrans,
extra_axis='grains',
rad_conv_bound=False)
Plotting the P-T profiles...
---------------------
Get posterior samples
---------------------
Database tag: 2mj1506
Random samples: None
Samples shape: (6301, 29)
Parameters:
- logg
- radius
- parallax
- t0
- t1
- t2
- t3
- t4
- t5
- t6
- t7
- t8
- t9
- t10
- t11
- t12
- t13
- t14
- metallicity
- c_o_ratio
- log_p_quench
- fsed
- log_kzz
- sigma_lnorm
- MgSiO3(s)_crystalline__DHS_fraction
- Fe(s)_crystalline__DHS_fraction
- pt_smooth
- rad_vel
- vsini
Loading chemical equilibrium chemistry table from file '/Users/tomasstolker/.petitradtrans/input_data/pre_calculated_chemistry/equilibrium_chemistry/equilibrium_chemistry.chemtable.petitRADTRANS.h5'... Done.

[DONE]
The plot_pt_profile function also returned the Figure object of the plot. The axes of the Figure are stored as the axes attribute.
[17]:
fig.axes
[17]:
[<Axes: xlabel='Temperature (K)', ylabel='Pressure (bar)'>,
<Axes: xlabel='Average particle radius (µm)'>]
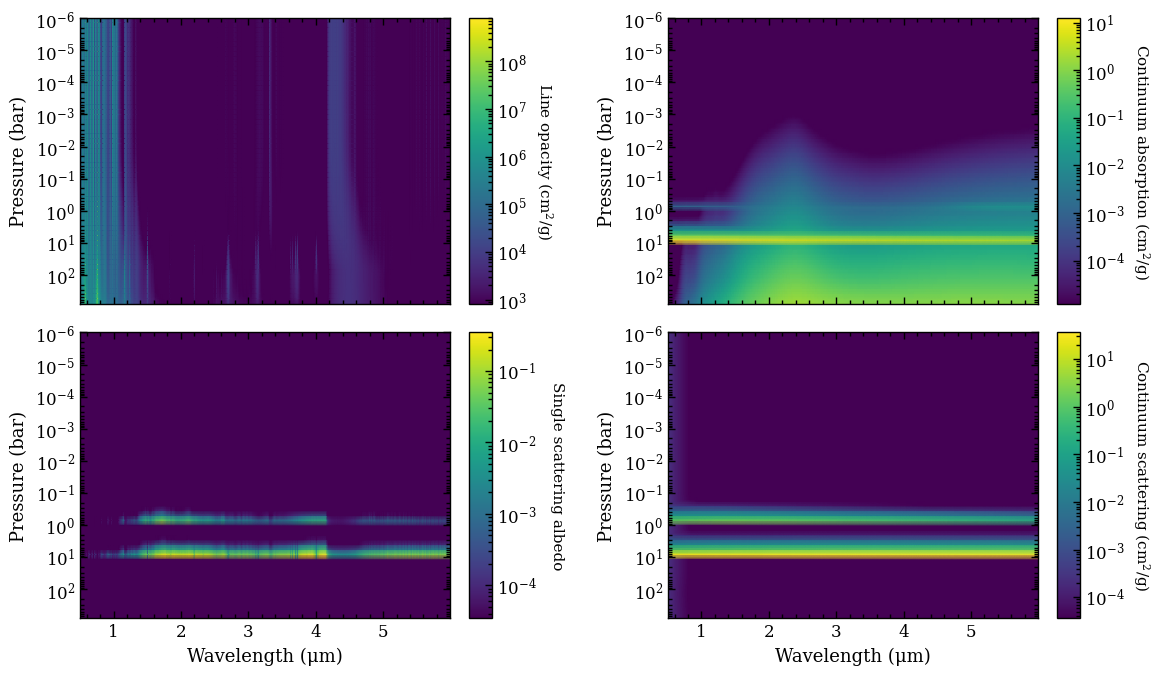
Next, we use the plot_opacities function for plotting the line and continuum opacities for the atmospheric structure of the median retrieved parameters. We pass again the ReadRadtrans object as argument of radtrans, which was earlier returned by
get_retrieval_spectra. The single scattering albedo is calculated as \(\omega = \frac{\kappa_\mathrm{cont,scat}}{\kappa_\mathrm{line} + \kappa_\mathrm{cont,abs} + \kappa_\mathrm{cont,scat}}\). The scattering opacity is dominated by the cloud decks of the two clouds species but the \(\lambda^{-4}\) dependence of the Rayleigh scattering from gas is also seen in the mass
opacities. However, the impact on the spectrum at infrared wavelengths is typically negligible. The function returns again the Figure object of the plot.
[18]:
# This function should be fixed after the upgrade to pRT 3.0
# fig = plot_opacities(tag='2mj1506',
# radtrans=radtrans,
# offset=(-0.1, -0.14),
# output=None)
For the cloud model, we used the parametrization from Mollière et al. (2020), which determines the cloud base through the intersection of the condensation profiles of the cloud species with the P-T profile. The vertical cloud structure is controlled by the \(f_\mathrm{sed}\) parameter and the average particle sizes by the eddy diffusion coefficient, \(K_\mathrm{zz}\). Furthermore, it uses a log-normal size distribution for the cloud particle with the width, \(\sigma_\mathrm{g}\), as free parameter. We can plot the size distributions as function of pressure with the plot_clouds. Here, we need to specify one of the two cloud species that were included with the retrieval and we need to provide again the ReadRadtrans object.
[19]:
fig = plot_clouds(tag='2mj1506',
offset=(-0.12, -0.15),
output=None,
radtrans=radtrans,
composition='MgSiO3(s)_crystalline__DHS')
---------------------
Get posterior samples
---------------------
Database tag: 2mj1506
Random samples: None
Samples shape: (6301, 29)
Parameters:
- logg
- radius
- parallax
- t0
- t1
- t2
- t3
- t4
- t5
- t6
- t7
- t8
- t9
- t10
- t11
- t12
- t13
- t14
- metallicity
- c_o_ratio
- log_p_quench
- fsed
- log_kzz
- sigma_lnorm
- MgSiO3(s)_crystalline__DHS_fraction
- Fe(s)_crystalline__DHS_fraction
- pt_smooth
- rad_vel
- vsini
Plotting MgSiO3(s)_crystalline__DHS clouds...
[DONE]
Creating a Box with the observed spectrum¶
After getting an impression of the retrieved atmospheric structure, we will create a plot of the data and model spectra. To do so, we need several functions to extract the relevant data from the database. First, we create an ObjectBox with the data (only a spectrum in this case) of 2MASS J15065441+1321060 by using the get_object method of Database.
[20]:
object_box = database.get_object('2MASS J15065441+1321060')
----------
Get object
----------
Object name: 2MASS J15065441+1321060
Include photometry: True
Include spectra: True
Let’s have a look at the content of the ObjectBox with open_box. This method can be used on any Box object.
[21]:
object_box.open_box()
Opening ObjectBox...
name = 2MASS J15065441+1321060
filters = []
mean_wavel = {}
magnitude = {}
flux = {}
spectrum = {'IRTF': (array([[9.3171155e-01, 6.2615632e-15, 1.2361384e-15],
[9.3198341e-01, 5.5975380e-15, 1.1189908e-15],
[9.3225533e-01, 6.5201217e-15, 9.6139224e-16],
...,
[4.0973549e+00, 1.8983273e-15, 4.6716408e-16],
[4.0981603e+00, 1.8976329e-15, 4.6592032e-16],
[4.0989652e+00, 1.6915271e-15, 4.6575150e-16]],
shape=(5399, 3), dtype=float32), None, None, np.float64(2000.0))}
parallax = [85.425 0.1902]
distance = None
Best-fit spectrum and residuals¶
We already drew 30 random spectra from the posterior distribution with get_retrieval_spectra, but in addition we will compute the spectrum with the best-fit parameters. Here, we adopt the median retrieved parameters as the best-fit values. We start extracting the median values with the get_median_sample method of Database.
[22]:
best = database.get_median_sample(tag='2mj1506')
---------------------
Get median parameters
---------------------
Database tag: 2mj1506
Parameters:
- logg = 5.75
- radius = 0.92
- parallax = 85.45
- t0 = 38.41
- t1 = 152.49
- t2 = 239.38
- t3 = 400.39
- t4 = 449.54
- t5 = 874.41
- t6 = 1198.74
- t7 = 1221.60
- t8 = 1338.60
- t9 = 1820.52
- t10 = 1833.47
- t11 = 2331.00
- t12 = 3675.19
- t13 = 4880.06
- t14 = 6687.26
- metallicity = 1.03
- c_o_ratio = 0.60
- log_p_quench = -2.04e-01
- fsed = 9.28
- log_kzz = 5.55
- sigma_lnorm = 1.20
- MgSiO3(s)_crystalline__DHS_fraction = -4.65e-01
- Fe(s)_crystalline__DHS_fraction = 0.99
- pt_smooth = 0.51
- rad_vel = -9.05e+00
- vsini = 81.01
The atmospheric parameters are stored in a dictionary. Some of the parameters, such as the distance and pt_smooth may not have been free parameters with the retrieval though, but are required for computing the spectrum.
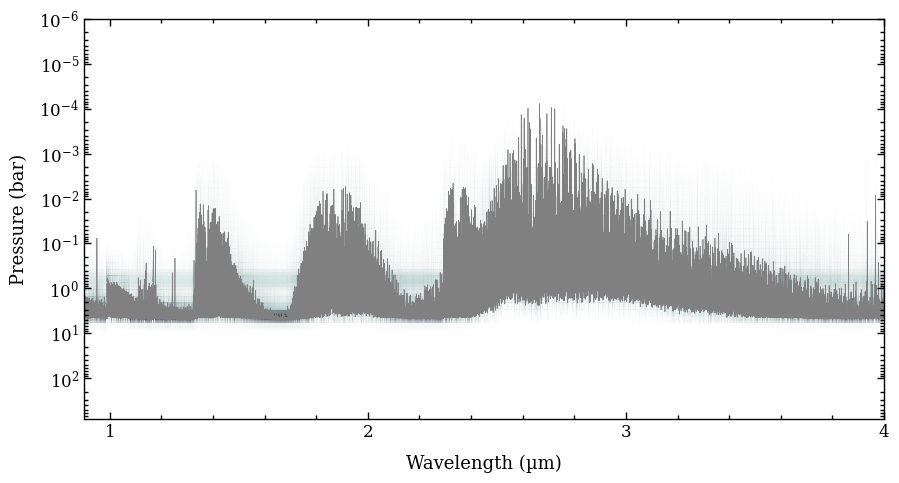
Next, we will compute the petitRADTRANS spectrum for the best-fit parameters at \(R = 2000\). The get_model method of the ReadRadtrans object requires a dictionary with parameters as argument. We also set plot_contribution=True such that a plot of the emission
contribution as function of pressure wavelength is shown.
[23]:
model_box = radtrans.get_model(model_param=best,
spec_res=2000.,
wavel_resample=None,
plot_contribution=True)
With the parameter dictionary, the ObjectBox with data, and the ReadRadtrans object, we can calculate the residuals (i.e. data minus model) of the best-fit spectrum. To do so, we use the get_residuals function, which calculates the residuals (relative to the data uncertainties) for each spectrum (only one in this case) and photometric flux, together with the reduced \(\chi^2\).
[24]:
res_box = get_residuals(tag='2mj1506',
parameters=best,
objectbox=object_box,
inc_phot=True,
inc_spec=True,
radtrans=radtrans)
-------------------
Calculate residuals
-------------------
Database tag: 2mj1506
Results type: AtmosphericRetrieval
Model: petitradtrans
Model parameters:
- logg
- radius
- parallax
- t0
- t1
- t2
- t3
- t4
- t5
- t6
- t7
- t8
- t9
- t10
- t11
- t12
- t13
- t14
- metallicity
- c_o_ratio
- log_p_quench
- fsed
- log_kzz
- sigma_lnorm
- MgSiO3(s)_crystalline__DHS_fraction
- Fe(s)_crystalline__DHS_fraction
- pt_smooth
- rad_vel
- vsini
Fixed parameters: none
Include photometry: True
Include spectra: True
Spectres: new_wavs contains values outside the range in spec_wavs, new_fluxes and new_errs will be filled with the value set in the 'fill' keyword argument.
Residuals (sigma):
- IRTF: min = -32.43, max = 45.73
Number of data points = 5275
Number of model parameters = 29
Number of fixed parameters = 0
Number of degrees of freedom = 5246
chi2 = 118666.57
reduced chi2 = 22.62
Let’s have a look at the content of the returned ResidualsBox with open_box.
[25]:
res_box.open_box()
Opening ResidualsBox...
name = 2MASS J15065441+1321060
photometry = {}
spectrum = {'IRTF': array([[ 0.93171155, -0.84780137],
[ 0.93198341, -1.35899361],
[ 0.93225533, -0.6646553 ],
...,
[ 4.09735489, nan],
[ 4.09816027, nan],
[ 4.09896517, nan]], shape=(5399, 2))}
chi2_red = 22.62038989662763
For comparison, we calculate a spectrum without the clouds to see their effect of the spectrum. This is done by simply setting the cloud mass fractions to \(10^{-100}\) and rerunning get_model with the updated parameter dictionary.
[26]:
no_cloud = best.copy()
no_cloud['MgSiO3(s)_crystalline__DHS_fraction'] = -100.
no_cloud['Fe(s)_crystalline__DHS_fraction'] = -100.
model_no_cloud = radtrans.get_model(no_cloud, spec_res=2000.)
Furthermore, we calculate a spectrum without accounting for scattering from (mainly) clouds to see the importance of scattering in the radiative transfer of cloudy atmospheres. We need to set the do_scat_emis and test_ck_shuffle_comp attributes of the Radtrans object (i.e. the rt_object of ReadRadtrans ) to False and rerun
get_model with the best-fit parameters.
[27]:
radtrans.rt_object.scattering_in_emission = False
model_no_scat = radtrans.get_model(best, spec_res=2000.)
/Users/tomasstolker/.pyenv/versions/3.12.7/envs/species3.12/lib/python3.12/site-packages/petitRADTRANS/radtrans.py:427: UserWarning: setting a Radtrans property directly is not recommended
Create a new Radtrans instance (recommended) or re-do all the setup steps necessary for the modification to be taken into account
warnings.warn(self.__property_setting_warning_message)
Plotting the SED with data and model spectra¶
We are now ready to create a plot of the spectral energy distribution (SED) to compare the data with the model spectra! The plot_spectrum function requires a list of Box objects as argument of boxes and the
ResidualsBox is passed as separate argument of residuals. For each box we can set the plot style, by providing a list with dictionaries as argument of plot_kwargs, in the same order as the list of boxes. Items in the list can be set to None, in which case some default values are used. Finally, there is a handful of parameters that can be adjusted for the appearance of the plot (see the
API documentation of plot_spectrum for details).
[28]:
fig = plot_spectrum(boxes=[samples, model_box, model_no_cloud, model_no_scat, object_box],
filters=None,
plot_kwargs=[{'ls': '-', 'lw': 0.1, 'color': 'gray'},
{'ls': '-', 'lw': 0.5, 'color': 'black'},
{'ls': '-', 'lw': 0.3, 'color': 'tab:orange', 'label': 'No clouds'},
{'ls': '-', 'lw': 0.3, 'color': 'tab:green', 'label': 'No scattering'},
{'IRTF': {'ls': '-', 'lw': 0.3, 'color': 'tab:blue', 'label': '2MASS J15065441+1321060'}}],
residuals=res_box,
xlim=(0.8, 4.2),
ylim=(0., 2.7e-14),
ylim_res=(-10., 10.),
scale=('linear', 'linear'),
offset=(-0.6, -0.05),
figsize=(8, 3),
legend={'loc': 'upper right', 'fontsize': 10.},
output=None,
leg_param=['logg', 'radius', 'feh', 'c_o_ratio', 'fsed'])
-------------
Plot spectrum
-------------
Boxes:
- List with 30 x ModelBox
- ModelBox
- ModelBox
- ModelBox
- ObjectBox
Object type: planet
Quantity: flux density
Units: ('um', 'W m-2 um-1')
Filter profiles: None
Figure size: (8, 3)
Legend parameters: ['logg', 'radius', 'feh', 'c_o_ratio', 'fsed']
Include model name: False
Font sizes: {'xlabel': 11.0, 'ylabel': 11.0, 'title': 13.0, 'legend': 9.0}
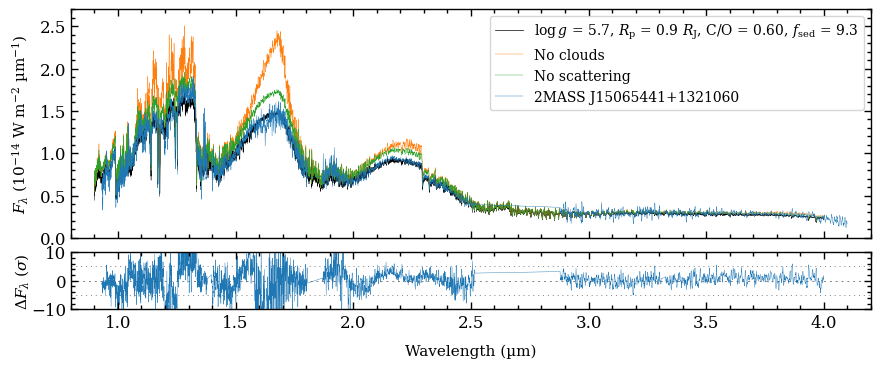
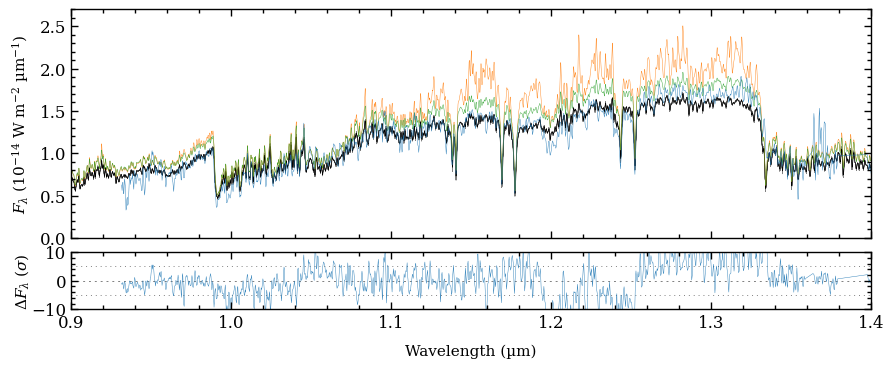
We can clearly see the impact of the clouds, which dampens the molecular absorption bands. The comparison also shows that scattering is important since the spectral fluxes would be overestimated otherwise.
Let’s zoom in on the \(Y\) and \(J\) bands to reveal the spectral features from species such as H\(_2\)O, FeH, Na, and K more clearly. Instead of rerunning the plot_spectrum function, we simply adjust the limits of the first item of the list with axes of the Figure.
[29]:
fig.axes[0].set_xlim(0.9, 1.4)
fig.axes[1].set_xlim(0.9, 1.4)
fig.axes[0].get_legend().remove()
We can plot again the figure by calling the Figure object. The plot can be stored with the savefig method of the Figure.
[30]:
fig
[30]: